Q 네트워크 (Q-Networks)
뉴럴 네트워크와 Q-Learning의 만남! Q-네트워크에 대해서 알아 보고 Gym에서 제공하는 문제를 해결하기 위해 QN을 모델링 하고 최적의 액션을 예측하는 알고리듬을 만들어 보자.
실제로 돌려 보고 싶으면 구글 코랩으로 ~
![]()
문제 (Problem)
👤 보스
뉴럴 네트워크를 강화 학습에 적용이 가능하다며?
아래 체육관(Gym)에 가서
‘CartPole’ 문제를 풀어 보게
⚙️ 엔지니어
오~ 드디어 딥러닝을 활용할 수 있겠구나!
문제 분석 (Problem Anaysis)

검은색 카트(Cart) 위에 막대기(Pole)를 살짝 올려 놓고
검은색 카트를 좌우로 움직여서 막대기가 쓰러지지 않도록 하는 것이 목표다. (조금만 잘못 움직여도 막대기는 쓰러진다…)
환경 (Environment)
‘CartPole’ 의 환경은 네종류의 상태(State)와 2개의 액션(Action)으로 구성 되어 있다.
import gym
import numpy as np
#
# Environment
#
env = gym.make('CartPole-v1')
state = env.reset()
action = env.action_space.sample()
print('State space: ', env.observation_space)
print('Initial state: ', state)
print('\nAction space: ', env.action_space)
print('Random action: ', action)State space: Box(4,)
Initial state: [ 0.02349072 0.03010665 0.03237231 -0.02729614]
Action space: Discrete(2)
Random action: 0
액션 (Action)
‘CartPole’에서는 2개의 액션이 존재한다. 그리고 각각의 액션이 번호로 지정 되어 있다.
\(A = \{0, 1\}\)
| Num | Action |
|---|---|
| 0 | Push cart to the left |
| 1 | Push cart to the right |
상태 (State)
‘CartPole’의 상태(State) \(S\)는 4개의 실수값의 배열로 되어 있다.
\(S = \begin{bmatrix} \{ s_{00}, s_{01}, \cdots\}, \\ \{ s_{10}, s_{11}, \cdots \}, \\ \{ s_{20}, s_{21}, \cdots \}, \\ \{ s_{30}, s_{31}, \cdots \} \end{bmatrix}\)
| Index | State | Min | Max |
|---|---|---|---|
| 0 | Cart Position | -4.8 | 4.8 |
| 1 | Cart Velocity | -Inf | Inf |
| 2 | Pole Angle | -24 deg | 24 deg |
| 3 | Pole Velocity At Tip | -Inf | Inf |
⚙️ 엔지니어
4종류의 상태값 중에 하나가 0.0000001만 바뀌어도
상태가 바뀐다.
다시말하면상태(State)가 무한대이다!
Q 테이블을 만드는 것은 불가능하다…
보상 (Reward)
매 스텝(step)마다 +1을 보상 받는다. 종료 스텝(termination step)에도 +1을 보상 받는다.
⚙️ 엔지니어
오래 버티면 높은 점수를 받는다!
Q-Network 모델링 (Modeling)
아이디어는 단순하다. 샘플링된 상태(State)와 Q-value 데이터를 가지고 전체 상태에 대한 Q-value를 예측 하겠다는 것이다. 그리고 우리는 뉴럴 네트워크가 예측(Prediction)을 아주 잘 한다는 것을 알고 있다!
아래와 같이 3-레이어 뉴럴 네트워크를 구성한다.
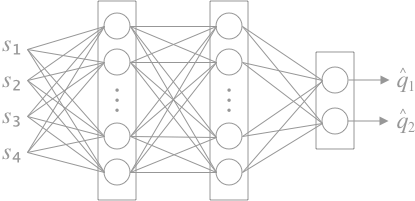
데이터 수집 (Data Collection)
입력 데이터 \(X\)는 상태(State), \(Y\)는 액션에 대한 Q-value (Q-Learning에서 타겟) 이다.
\(\begin{align}
& X = \{ s_1^{(i)}, s_2^{(i)}, s_3^{(i)}, s_4^{(i)} \} \\
& s_1^{(i)} : \text{i 번째 Cart Position 값} \\
& s_2^{(i)} : \text{i 번째 Cart Velocity 값} \\
& s_3^{(i)} : \text{i 번째 Pole Angle 값} \\
& s_4^{(i)} : \text{i 번째 Pole Velocity At Tip 값} \\
\\
& Y = \{ q_1^{(i)}, q_2^{(i)} \} \\
& q_1^{(i)} = r^{(i)} + \gamma \max_{a_0} q^{(i)}(s_{t+1}, a_0), \quad \text{i 번째 0번 액션에 대한 Q-value} \\
& q_2^{(i)} = r^{(i)} + \gamma \max_{a_1} q^{(i)}(s_{t+1}, a_1), \quad \text{i 번째 1번 액션에 대한 Q-value}
\end{align}\)
모델링 (Modeling)
\(\begin{align} & \hat Y = \{ \hat q_1^{(i)}, \hat q_2^{(i)} \} \\ & \hat q_1^{(i)} = Q(s, a_0, w) \\ & \hat q_2^{(i)} = Q(s, a_1, w) \end{align}\)
손실 함수 (Loss Function)
\(\begin{align} J(w) & = \mathbb E_{\pi} [(q - \hat q)^2] \\ & = \mathbb E_{\pi} \left [\left (R_{t+1} + \gamma \max_{a’} Q(S_{t+1}, a’) - Q(S_t, A_t, w) \right)^2 \right ] \end{align}\)
경사 하강법 (Gradient Descent)
REPEAT(epoch) {
\( w \leftarrow w-\alpha \dfrac{\partial J(w)}{\partial w}\)
}
최적의 액션 예측 (Predict Optimal Action)
\(\hat A_t = \text{argmax}_{a’}Q(S_t, a’, w)\)
케라스(Keras)로 모델링 (Modeling)
- 히든 레이어(hidden layer) 정의
- 히든 레이어 개수를 정의한다. 여기서는 2-hidden layer를 사용한다.
- 히든 레이어 유닛 개수를 정의한다. 여기서는 32개, 32개 유닛을 사용한다.
- 활성 함수(activation function)를 정의한다. 여기서는 ReLU 를 사용한다.
- 히든 레이어 개수를 정의한다. 여기서는 2-hidden layer를 사용한다.
- 출력 레이어(output layer) 정의
- 출력 레이어 유닛 개수를 정의한다. 여기서는 각 액션에 대한 Q-value이므로 2개 유닛을 사용한다.
- 출력 레이어 유닛 개수를 정의한다. 여기서는 각 액션에 대한 Q-value이므로 2개 유닛을 사용한다.
- 손실 함수 (Loss function)를 정의한다. 평균 제곱 오차(mean squared error) 를 사용한다.
옵티마이저(Optimizer)를 정의한다. 여기서는 Adam 을 사용한다.
# Q-Network Modeling from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense num_state = env.observation_space.shape[0] num_action = env.action_space.n model = Sequential() model.add(Dense(32, input_dim= num_state, activation='relu')) model.add(Dense(32, activation='relu')) model.add(Dense(num_action, activation=None)) model.compile(loss='mse', optimizer="adam")
에이전트 (Agent)
𝜀-greedy 방식으로 탐색하면서 데이터를 수집한다.
메모리 (Memory)
Q-Learning에서 얻은 데이터 (\(s_t, a_t, r_{t+1}, s_{t+1}\)) 들을 뉴럴 네트워크에서 사용하기 위해서 메모리에 저장한다.
\(\text{memory} = [(s_0, a_0, r_1, s_1), (s_1, a_1, r_2, s_2), \cdots]\)
리플레이 (Replay)
메모리에 저장된 데이터들을 QN 모델에 넣고 훈련한다.
학습 (Learning)
돌려 놓고 커피 한잔 하세여~ ☕️
from tqdm import tqdm
num_iteration = 500
min_timesteps_per_batch = 2500
# Hyper parameter
epsilon = 0.3
gamma = 0.95
batch_size = 32
# Q-Network Learning
for i in tqdm(range(num_iteration)):
timesteps_this_batch = 0
memory = []
while True:
state = env.reset()
done = False
while not done:
if np.random.uniform() < epsilon:
action = env.action_space.sample()
else:
q_value = model.predict(state.reshape(1, num_state))
action = np.argmax(q_value[0])
next_state, reward, done, info = env.step(action)
# Memory
memory.append((state, action, reward, next_state, done))
state = next_state
timesteps_this_batch += len(memory)
if timesteps_this_batch > min_timesteps_per_batch:
break
# Replay
for state, action, reward, next_state, done in memory:
if done:
target = reward
else:
target = reward + gamma * (np.max(model.predict(next_state.reshape(1, num_state))[0]))
q_value = model.predict(state.reshape(1, num_state))
q_value[0][action] = target
model.fit(state.reshape(1, num_state), q_value, epochs=1, batch_size=32, verbose=0)
env.close()100%|██████████| 500/500 [20:35<00:00, 3.16s/it]
모델 저장 (Save Model)
import os
save_dir = os.getcwd()
model_name = 'keras_dqn_trained_model.h5'
# Save model and weights
model_path = os.path.join(save_dir, model_name)
model.save(model_path)해결 (Solution)
저장된 모델을 이용해서 어떠한 상태(state)에서도 최적의 Q-value와 액션(action)을 예측한다. CartPole의 동작을 비디오로 저장해서 잘 동작 하는지 확인하자!
학습된 CartPole의 묘기를 비디오로 저장하기 위한 코드이다.
!pip install gym pyvirtualdisplay!apt-get install xvfb python-opengl ffmpegfrom gym.wrappers import Monitor
import base64
from IPython.display import HTML
from IPython import display as ipythondisplay
from pyvirtualdisplay import Display
display = Display(visible=0, size=(1400, 900))
display.start()
def show_video(file_infix):
with open('./video/openaigym.video.%s.video000000.mp4' % file_infix, 'r+b') as f:
video = f.read()
encoded = base64.b64encode(video)
ipythondisplay.display(HTML(data='''<video alt="Trained CartPole" autoplay
loop style="height: 200px;">
<source src="data:video/mp4;base64,{0}" type="video/mp4" />
</video>'''.format(encoded.decode('ascii'))))
def wrap_env(env):
env = Monitor(env, './video', force=True)
return envW1008 12:17:57.362279 140568074921792 abstractdisplay.py:151] xdpyinfo was not found, X start can not be checked! Please install xdpyinfo!
저장된 모델을 불러온다.
from tensorflow.keras.models import load_model
import os
load_dir = os.getcwd()
model_name = 'keras_dqn_trained_model.h5'
model_path = os.path.join(load_dir, model_name)
model = load_model(model_path)막대기가 쓰러지지 않도록 카트를 잘 조종하고 있다!
import gym
import numpy as np
env = wrap_env(gym.make('CartPole-v1'))
num_state = env.observation_space.shape[0]
state = env.reset()
done = False
while not done:
state = np.array(state).reshape(1, num_state)
q_value = model.predict(state)
action = np.argmax(q_value[0])
state, reward, done, info = env.step(action)
file_infix = env.file_infix
env.close()
show_video(file_infix)- 참고한 코드는 아래와 같다.
https://github.com/keon/deep-q-learning