Long Short-Term Memory (LSTM)
감성 분석(Sentiment Analysis)을 위해서 텍스트 데이터를 변환하는 방법과 LSTM에 대해 알아보고 keras를 이용해서 모델링을 해보자!
실제로 돌려 보고 싶으면 구글 코랩으로 ~
![]()
문제 (Problem)
👤 상사
오~ 간단한 감성 분석기를 만들었군
근데 이건 애들 장난이고…
네이버가 제공하는 영화 리뷰 데이터로
제대로 된 감성 분석기를 만들어 보게
데이터는 아래에 있네
⚙️ 엔지니어
프로젝트가 쌓여만 간다…
이제
떠날 때가 된것인가…
데이터 수집 (Data Collection)
https://github.com/e9t/nsmc 에서 데이터 정보를 알아보자
Data description - Each file is consisted of three columns: id, document, label - id: The review id, provieded by Naver - document: The actual review - label: The sentiment class of the review. (0: negative, 1: positive) - Columns are delimited with tabs (i.e., .tsv format; but the file extension is .txt for easy access for novices) - 200K reviews in total - ratings.txt: All 200K reviews - ratings_test.txt: 50K reviews held out for testing - ratings_train.txt: 150K reviews for training
Characteristics - All reviews are shorter than 140 characters - Each sentiment class is sampled equally (i.e., random guess yields 50% accuracy) - 100K negative reviews (originally reviews of ratings 1-4) -100K positive reviews (originally reviews of ratings 9-10) - Neutral reviews (originally reviews of ratings 5-8) are excluded
⚙️ 엔지니어
ratings_test.txt, ratings_train.txt를 다운로드 하자
from tensorflow.keras.utils import get_file
train_fname = 'ratings_train.tsv'
test_fname = 'ratings_test.tsv'
train_origin = 'https://raw.github.com/e9t/nsmc/master/ratings_train.txt'
test_origin = 'https://raw.github.com/e9t/nsmc/master/ratings_test.txt'
train_path = get_file(train_fname, train_origin)
test_path = get_file(test_fname, test_origin)Rating 데이터 프레임
import pandas as pd
import numpy as np
train_df = pd.read_csv(train_path, sep='\t') # tsv file
train_df.head()| id | document | label | |
|---|---|---|---|
| 0 | 9976970 | 아 더빙.. 진짜 짜증나네요 목소리 | 0 |
| 1 | 3819312 | 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 | 1 |
| 2 | 10265843 | 너무재밓었다그래서보는것을추천한다 | 0 |
| 3 | 9045019 | 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 | 0 |
| 4 | 6483659 | 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 ... | 1 |
test_df = pd.read_csv(test_path, sep='\t') # tsv file
test_df.head()| id | document | label | |
|---|---|---|---|
| 0 | 6270596 | 굳 ㅋ | 1 |
| 1 | 9274899 | GDNTOPCLASSINTHECLUB | 0 |
| 2 | 8544678 | 뭐야 이 평점들은.... 나쁘진 않지만 10점 짜리는 더더욱 아니잖아 | 0 |
| 3 | 6825595 | 지루하지는 않은데 완전 막장임... 돈주고 보기에는.... | 0 |
| 4 | 6723715 | 3D만 아니었어도 별 다섯 개 줬을텐데.. 왜 3D로 나와서 제 심기를 불편하게 하죠?? | 0 |
데이터 분석 (Data Analysis)
빵꾸난거 부터 확인하고 제거하자
train_df.isnull().any()id False
document True
label False
dtype: bool
train_df = train_df.dropna(axis=0).reset_index(drop=True)test_df.isnull().any()id False
document True
label False
dtype: bool
test_df = test_df.dropna(axis=0).reset_index(drop=True)데이터의 크기와 레이블에 따른 분포를 확인하자
print('Train data shape: ', train_df.shape)
n_lebel = len(train_df[train_df.label == 0])
print('Label 0 in Train data: {} ({:.1f}%)'.format(n_lebel, n_lebel*100/len(train_df)))
n_lebel = len(train_df[train_df.label == 1])
print('Label 1 in Train data: {} ({:.1f}%)'.format(n_lebel, n_lebel*100/len(train_df)))
print('\nTest data shape: ', test_df.shape)
n_lebel = len(test_df[test_df.label == 0])
print('Label 0 in Test data: {} ({:.1f}%)'.format(n_lebel, n_lebel*100/len(test_df)))
n_lebel = len(test_df[test_df.label == 1])
print('Label 1 in Test data: {} ({:.1f}%)'.format(n_lebel, n_lebel*100/len(test_df)))Train data shape: (149995, 3)
Label 0 in Train data: 75170 (50.1%)
Label 1 in Train data: 74825 (49.9%)
Test data shape: (49997, 3)
Label 0 in Test data: 24826 (49.7%)
Label 1 in Test data: 25171 (50.3%)
id컬럼은 필요 없으니 제거하자.
train_df = train_df[['document', 'label']]
test_df = test_df[['document', 'label']]데이터 전처리 (Data Preprocessing)
한글 텍스트를 RNN에 입력하기 위해서는 텍스트를 RNN이 처리하기 편한 형태로 분리해야 한다. 이렇게 텍스트를 분리하는 작업을 토근화(Tokenization) 라고 한다.
한글을 토큰화 하기 위해서 형태소 분석기를 사용한다. 다양한 한글 형태소 분석기가 존재하는데, 여기에서는 PyKomoran을 사용한다. 다른 형태소 분석기에 관심이 있으면 아래를 참조한다.
⚙️ 엔지니어
앞에서 본 이모티콘 감성분석에서
이모티콘을 텍스트로 변환했는데
반대로
텍스트를 이모티콘으로 변환하는 것을
토큰화(Tokenization)라고 생각하면
이해가 쉬울 것 같다…
형태소 분석기 설치
PyKomoran을 사용하기 위해서는 Java가 설치 되어 있어야 한다. 아래 명령어를 실행해서 Java가 설치되어 있는지 확인하자.
!java -versionopenjdk version "1.8.0_152-release"
OpenJDK Runtime Environment (build 1.8.0_152-release-1056-b12)
OpenJDK 64-Bit Server VM (build 25.152-b12, mixed mode)
PyKomoran을 설치한다.
%pip install PyKomoranCollecting PyKomoran
[?25l Downloading https://files.pythonhosted.org/packages/23/b0/ce6a46f311651ed64c39beb1cfe1c39a9906521139ace45430d08c489b62/PyKomoran-0.1.5-py3-none-any.whl (7.9MB)
[K |████████████████████████████████| 7.9MB 1.2MB/s eta 0:00:01
[?25hCollecting py4j==0.10.8.1 (from PyKomoran)
[?25l Downloading https://files.pythonhosted.org/packages/04/de/2d314a921ef4c20b283e1de94e0780273678caac901564df06b948e4ba9b/py4j-0.10.8.1-py2.py3-none-any.whl (196kB)
[K |████████████████████████████████| 204kB 2.1MB/s eta 0:00:01
[?25hInstalling collected packages: py4j, PyKomoran
Successfully installed PyKomoran-0.1.5 py4j-0.10.8.1
Note: you may need to restart the kernel to use updated packages.
설치 확인을 위해 아래 코드를 실행한다.
from PyKomoran import *
corpus = "① 대한민국은 민주공화국이다."
komoran = Komoran("STABLE")
komoran.get_plain_text(corpus)'①/SW 대한민국/NNP 은/JX 민주/NNP 공화국/NNG 이/VCP 다/EF ./SF'
토큰화 (Tokenization)
형태소 분석기는 문장을 품사(PoS)별로 분리해 준다. 모든 품사를 사용하지 않고 감성 분석에 필요하다고 판단이 되는 품사를 선정해서 토큰화를 진행한다.
품사 (Part Of Speech)
Komoran에서 정의하는 품사 종류는 아래 사이트를 참조.
품사표 (PoS Table): https://pydocs.komoran.kr/firststep/postypes.html
불용어 (Stop Words)
RNN에 입력으로 들어가지 못하는 단어들을 말한다. 여기서는 들어가지 못하는 품사를 아래와 같이 정의한다.
stop_pos_tags = ['IC', 'JKS', 'JKC', 'JKG', 'JKO', 'JKB', 'JKV', 'JKQ', 'JX',
'EF', 'ETN', 'ETM', 'XSA', 'SF', 'SP', 'SS', 'SE', 'SO', 'SL', 'SH',
'SW', 'NF', 'NV', 'SN', 'NA']어간 원형 복원 (Lemmatization)
동사와 형용사의 경우에는 어간(Stem)에 ‘다’를 붙여서 기본형으로 복원한다.
def tokenize(corpus, stop_pos_tags):
result = []
pairs = komoran.get_list(corpus)
for pair in pairs:
morph = pair.get_first()
pos = pair.get_second()
if pos not in stop_pos_tags:
if pos in ['VV', 'VA', 'VX', 'VCP', 'VCN']:
morph = morph + '다'
result.append(morph)
return result토큰을 만들고 리스트에 저장한다.
tokens_list = []
for i in range(len(train_df['document'])):
tokens_list.append(tokenize(train_df['document'][i], stop_pos_tags))데이터 프레임에 넣어서 토큰이 제대로 만들어 졌는지 확인한다.
train_df['tokens'] = tokens_list
train_df.head()| document | label | tokens | |
|---|---|---|---|
| 0 | 아 더빙.. 진짜 짜증나네요 목소리 | 0 | [더빙, 진짜, 짜증, 나다, 네요, 목소리] |
| 1 | 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 | 1 | [포스터, 초, 딩, 영화, 줄, 오버, 연기, 가볍다, 지, 않다, 구나] |
| 2 | 너무재밓었다그래서보는것을추천한다 | 0 | [] |
| 3 | 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 | 0 | [교도소, 이야기, 이다, 구먼, 솔직히, 재미, 없다, 평점, 조정] |
| 4 | 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 ... | 1 | [익살, 연기, 돋보이다, 었, 영화, 스파이, 더, 맨, 늙다, 어, 보이다, 하... |
토큰이 비어있는 열은 과감하게 제거한다.
train_df = train_df[train_df['tokens'].str.len() > 2]테스트 데이터도 동일하게 토큰을 추출하고 데이터프레임에 저장한다.
tokens_list = []
for i in range(len(test_df['document'])):
tokens_list.append(tokenize(test_df['document'][i], stop_pos_tags))
test_df['tokens'] = tokens_list
test_df.head()| document | label | tokens | |
|---|---|---|---|
| 0 | 굳 ㅋ | 1 | [굳다] |
| 1 | GDNTOPCLASSINTHECLUB | 0 | [] |
| 2 | 뭐야 이 평점들은.... 나쁘진 않지만 10점 짜리는 더더욱 아니잖아 | 0 | [뭐, 이, 평점, 들, 나쁘다, 지, 않다, 지만, 점, 짜리, 더더욱, 아니다,... |
| 3 | 지루하지는 않은데 완전 막장임... 돈주고 보기에는.... | 0 | [지루, 지, 않다, 은데, 완전, 막장, 이다, 돈, 주다, 고, 보다] |
| 4 | 3D만 아니었어도 별 다섯 개 줬을텐데.. 왜 3D로 나와서 제 심기를 불편하게 하죠?? | 0 | [아니다, 었, 어도, 별, 다섯, 개, 주다, 었, 텐, 데, 왜, 나오다, 아서... |
토큰이 비어있는 열은 과감하게 제거한다.
test_df = test_df[test_df['tokens'].str.len() > 2]LSTM 모델링 (LSTM Modeling)
RNN의 단점은 timestep이 증가하면 이전의 입력 데이터 정보가 사라진다는 것이다. 긴 문장의 경우에 timestep이 수백개가 되는 경우가 있다. 즉 RNN 레이어가 수백개가 되면 손실함수의 최소값을 찾기 위해 미분의 미분의 … 미분을 수백번을 하게 되고 어느 지점 부터 미분값이 0이 되면 그 이전의 입력 데이터 정보는 사용할 수 없게 된다.
⚙️ 엔지니어
RNN이 알고보니
‘메멘토’ 였다!그러나 엔지니어를 또 갈아서 해결했다.
그것은 바로…
LSTM (Long Short-Term Memory)
RNN unit에 이전 데이터의 정보를 저장하고 있는 메모리 셀(memory cell) 함수(\(c^{\lt t \gt}\))와 메모리 셀을 유지할 것인지 업데이트 할 것인지를 결정하는 게이트(gate) 함수(\(\Gamma_u, \Gamma_f, \Gamma_o\))를 추가한 것이 LSTM이다.
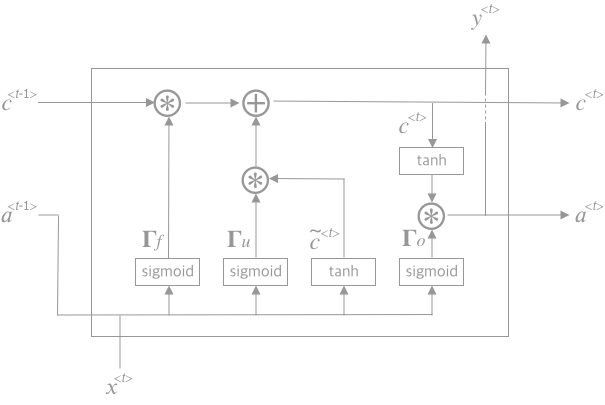
\(\begin{align} \tilde c^{\lt t \gt} & = tanh\left(W_{ca}a^{\lt t-1 \gt} + W_{cx}x^{\lt t \gt} + b_c\right) \\ \Gamma_u & = \sigma \left( W_{ua}a^{\lt t-1 \gt} + W_{ux}x^{\lt t \gt} + b_u \right) \\ \Gamma_f & = \sigma \left( W_{fa}a^{\lt t-1 \gt} + W_{fx}x^{\lt t \gt} + b_f \right) \\ \Gamma_o & = \sigma \left( W_{oa}a^{\lt t-1 \gt} + W_{ox}x^{\lt t \gt} + b_o \right) \\ c^{\lt t \gt} & = \Gamma_u * \tilde c^{\lt t \gt} + \Gamma_f * c^{\lt t-1 \gt} \\ a^{\lt t \gt} & = \Gamma_o * tanh (c^{\lt t \gt}) \\ \hat y^{\lt t \gt} & = W_{ya}a^{\lt t \gt} + b_y \end{align}\)
⚙️ 엔지니어
게이트(\(\Gamma\))의 열고(\(\Gamma = 1\)) 닫고(\(\Gamma = 0\))를
학습에 의해서 결정 (\((W_u, b_u), (W_f, b_f), (W_o, b_o)\)) 한다.
게이트(\(\Gamma\))의 상태에 따라서
메모리 셀 (\(c^{\lt t \gt}\))을 업데이트 할건지 (\(\tilde c^{\lt t \gt}\))
이전것을 유지할건지 (\(c^{\lt t-1 \gt}\)) 결정한다.트랜지스터 같네…
Many-to-One Model
감성분석(Sentiment Anaysis)에 사용되는 many to one 모델을 사용한다.
훈련 리뷰 개수 136,927개를 사용하고, time step은 40으로 고정한다.
리뷰마다 토큰의 수가 다르므로 40이 안되면 0으로 채우고(padding) 40이 넘으면 그 이상은 잘라 버린다(clipping)
정리
- Input Layer
- Batch size는 136927개
- Time step은 40개 (\(T_x = 40\))
- Feature 개수는 입력에 들어가는 토큰 1개
- Batch size는 136927개
- LSTM Layer
- 128개 유닛으로 구성한다.
- Dropout을 0.2로 설정한다.
- 128개 유닛으로 구성한다.
- Output Layer
- 활성 함수는 시그모이드(Sigmoid)를 사용한다.
- Loss funtion 은 binary_crossentropy 를 사용한다.
- Optimizer 는 Adam을 사용한다.
케라스(Keras)로 모델링(Modeling)
데이터 변환 (Data Transformation)
토큰을 숫자로 변환(Encoding)하고, 입력 토큰의 개수를 동일한 크기로 맞춘다. 출력은 0과 1로 변환한다.
Encoding
토큰을 숫자로 변환하고 tokenizer를 파일에 저장한다.
from tensorflow.keras.preprocessing.text import Tokenizer
import os
import pickle
tokenizer_name = 'keras_naver_review_tokenizer.pickle'
save_path = os.path.join(os.getcwd(), tokenizer_name)
max_words = 35000
tokenizer = Tokenizer(num_words=max_words, oov_token = True)
tokenizer.fit_on_texts(train_df.tokens)
train_df.tokens = tokenizer.texts_to_sequences(train_df.tokens)
test_df.tokens = tokenizer.texts_to_sequences(test_df.tokens)
with open(save_path, 'wb') as f:
pickle.dump(tokenizer, f, protocol=pickle.HIGHEST_PROTOCOL)
train_df.head()| document | label | tokens | |
|---|---|---|---|
| 0 | 아 더빙.. 진짜 짜증나네요 목소리 | 0 | [502, 31, 210, 66, 70, 716] |
| 1 | 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 | 1 | [489, 305, 236, 2, 172, 1294, 42, 717, 16, 34,... |
| 3 | 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 | 0 | [5551, 138, 3, 3988, 281, 87, 17, 46, 2881] |
| 4 | 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 ... | 1 | [6734, 42, 845, 10, 2, 1602, 67, 414, 1156, 12... |
| 5 | 막 걸음마 뗀 3세부터 초등학교 1학년생인 8살용영화.ㅋㅋㅋ...별반개도 아까움. | 0 | [678, 13857, 1512, 264, 1678, 1452, 471, 3, 80] |
test_df.head()| document | label | tokens | |
|---|---|---|---|
| 2 | 뭐야 이 평점들은.... 나쁘진 않지만 10점 짜리는 더더욱 아니잖아 | 0 | [54, 18, 46, 13, 456, 16, 34, 35, 26, 605, 314... |
| 3 | 지루하지는 않은데 완전 막장임... 돈주고 보기에는.... | 0 | [78, 16, 34, 238, 128, 340, 3, 140, 22, 5, 4] |
| 4 | 3D만 아니었어도 별 다섯 개 줬을텐데.. 왜 3D로 나와서 제 심기를 불편하게 하죠?? | 0 | [41, 10, 243, 191, 1942, 109, 22, 10, 671, 188... |
| 5 | 음악이 주가 된, 최고의 음악영화 | 1 | [216, 3476, 45, 49, 216, 2] |
| 7 | 마치 미국애니에서 튀어나온듯한 창의력없는 로봇디자인부터가,고개를 젖게한다 | 0 | [1060, 395, 372, 4329, 282, 11, 6400, 17, 1378... |
X_train = train_df.tokens
Y_train = train_df.label
X_test = test_df.tokens
Y_test = test_df.label
print('X_train shape: ', X_train.shape)
print('Y_train shape: ', Y_train.shape)
print('\nX_test shape: ', X_test.shape)
print('Y_test shape: ', Y_test.shape)X_train shape: (136927,)
Y_train shape: (136927,)
X_test shape: (45780,)
Y_test shape: (45780,)
Padding
Time step은 40으로 고정한다. 리뷰마다 토큰의 수가 다르므로 40이 안되면 0으로 채우고(padding) 40이 넘으면 그 이상은 잘라 버린다(clipping)
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len=40
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
print('X_train shape: ', X_train.shape)
print('X_test shape: ', X_test.shape)X_train shape: (136927, 40)
X_test shape: (45780, 40)
이진 분류 (Binary classification)
출력 데이터를 0과 1로 변환한다.
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
# Train
batch_size = Y_train.shape[0]
input_dim = 1
Y_train = encoder.fit_transform(Y_train) # Labeling
Y_train = np.reshape(Y_train, (batch_size, input_dim)) # Reshape
# Test
batch_size = Y_test.shape[0]
Y_test = encoder.transform(Y_test) # Labeling
Y_test = np.reshape(Y_test, (batch_size, input_dim)) # Reshape
print(Y_train.shape)
print(Y_test.shape)(136927, 1)
(45780, 1)
모델링 (Modeling)
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM
model = Sequential()
model.add(Embedding(max_words, 128))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])모델 훈련 (Train Model)
커피 한잔 하세여~ ☕️
hist = model.fit(X_train, Y_train, batch_size=32, epochs=5)Epoch 1/5
136927/136927 [==============================] - 429s 3ms/sample - loss: 0.3903 - acc: 0.8231
Epoch 2/5
136927/136927 [==============================] - 429s 3ms/sample - loss: 0.3104 - acc: 0.8662
Epoch 3/5
136927/136927 [==============================] - 430s 3ms/sample - loss: 0.2687 - acc: 0.8867
Epoch 4/5
136927/136927 [==============================] - 430s 3ms/sample - loss: 0.2322 - acc: 0.9037
Epoch 5/5
136927/136927 [==============================] - 430s 3ms/sample - loss: 0.1984 - acc: 0.9197
모델 테스트 (Test Model)
loss, acc = model.evaluate(X_test, Y_test, batch_size=32)
print('Test loss:', loss)
print('Test accuracy:', acc)45780/45780 [==============================] - 24s 519us/sample - loss: 0.4006 - acc: 0.8480
Test loss: 0.4006009472697622
Test accuracy: 0.8479904
모델 저장 (Save Model)
import os
save_dir = os.getcwd()
model_name = 'keras_naver_review_trained_model.h5'
# Save model and weights
model_path = os.path.join(save_dir, model_name)
model.save(model_path)
print('Saved trained model at %s ' % model_path)Saved trained model at /home/dataman/myWork/deeplearning/keras_naver_review_trained_model.h5
해결 (Solution)
⚙️ 엔지니어
review_text에 리뷰를 적어서 실행하면
감성 분석 예측 결과가 나옵니다.
정확도는 84% 입니다.
from tensorflow.keras.models import load_model
import os
import pickle
def load_tokenizer(path):
with open(path, 'rb') as f:
tokenizer = pickle.load(f)
return tokenizer
load_dir = os.getcwd()
model_name = 'keras_naver_review_trained_model.h5'
tokenizer_name = 'keras_naver_review_tokenizer.pickle'
model_path = os.path.join(load_dir, model_name)
tokenizer_path = os.path.join(load_dir, tokenizer_name)
model = load_model(model_path)
tokenizer = load_tokenizer(tokenizer_path)import numpy as np
from PyKomoran import *
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len=40
komoran = Komoran("STABLE")
stop_pos_tags = ['IC', 'JKS', 'JKC', 'JKG', 'JKO', 'JKB', 'JKV', 'JKQ', 'JX',
'EF', 'ETN', 'ETM', 'XSA', 'SF', 'SP', 'SS', 'SE', 'SO', 'SL', 'SH',
'SW', 'NF', 'NV', 'SN', 'NA']
def tokenize(corpus, stop_pos_tags):
result = []
pairs = komoran.get_list(corpus)
for pair in pairs:
morph = pair.get_first()
pos = pair.get_second()
if pos not in stop_pos_tags:
if pos in ['VV', 'VA', 'VX', 'VCP', 'VCN']:
morph = morph + '다'
result.append(morph)
return result
def predict_sentiment(text, model):
tokens = []
tokens.append(tokenize(text, stop_pos_tags))
tokens = tokenizer.texts_to_sequences(tokens)
x_test = pad_sequences(tokens, maxlen=max_len)
predict = model.predict(x_test)
if predict[0] > 0.5:
return 'GOOD'
else:
return 'BAD'
review_text = '재미있는영화입니다.'
result = predict_sentiment(review_text, model)
print('{} : {}'.format(review_text, result))재미있는영화입니다. : GOOD